July 14, 2024
Language Models are Few-Shot Learners
Link: https://papers.nips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
Language models have been a significant area of research in the field of artificial intelligence, particularly in natural language processing (NLP). The concept of few-shot learning, where a model learns from a small number of examples, has been a challenging problem for many years. Recently, however, advancements have been made in this area, with language models demonstrating improved task-agnostic, few-shot performance. This article will explore the findings presented in the paper "Language Models are Few-Shot Learners", which was presented at the Advances in Neural Information Processing Systems (NeurIPS) 2020 conference.
The authors of the paper trained GPT-3, an autoregressive language model with 175 billion parameters, 10 times more than any previous non-sparse language model. They tested its performance in the few-shot setting, applying GPT-3 without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
GPT-3 achieved strong performance on many NLP datasets, including translation, question-answering, and cloze tasks. It also performed well on several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic 5.
However, the paper also identified some datasets where GPT-3's few-shot learning still struggled, as well as some datasets where GPT-3 faced methodological issues related to training on large web corpora.
Few-Shot Learning (FSL) is a machine learning framework that allows a pre-trained model to generalize over new categories of data (that the pre-trained model has not seen during training) using only a few labeled samples per class. This approach falls under the paradigm of meta-learning, which means learning to learn 1.
Just like humans, who can identify new classes of data easily using only a few examples, FSL aims to mimic the same. For instance, if you go to an exotic zoo for the first time and see a particular bird you've never seen before, you might be given a set of three cards, each containing two images of different species of birds. By looking at the images on the cards and the bird in the zoo, you would be able to infer the bird species quite easily. Here, you learned the species of the bird yourself using some supporting information. This is what meta-learning tries to replicate 1.
In the context of FSL, there are typically two types of sets of data: the support set and the query set. The support set consists of the n labeled images of each K class, i.e., N * K total examples. These examples are used for learning how to solve a task. The query set consists of further examples of the same classes, which are used to evaluate the performance of this task. Each task can be completely non-overlapping; we may never see the classes from one task in any of the others.
The concept of few-shot learning can be extended to One-Shot Learning (where only one example is provided per class), Zero-Shot Learning (where no examples are provided per class), and N-Shot Learning (where N examples are provided per class). N-Shot Learning is seen as a broader concept than Few-Shot Learning, as Few-Shot, One-Shot, and Zero-Shot Learning are considered sub-fields of N-Shot Learning.
How does Few-shot learning work:
Few-shot learning (FSL) can be considered as a meta-learning problem where the model learns how to learn to solve the given problem.
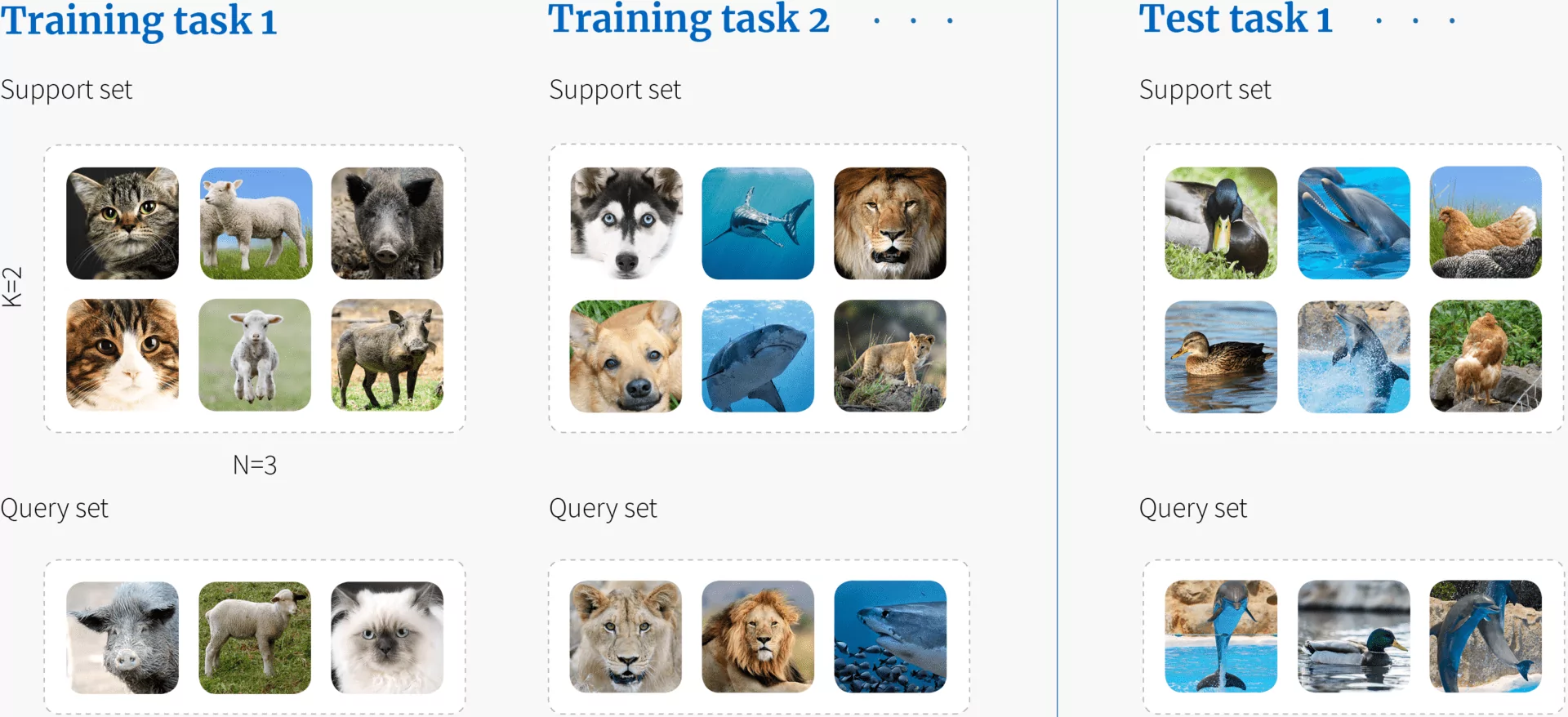
Here, each task mimics the few-shot scenario, so for N-way-K-shot classification, each task includes classes with examples of each. These are known as the support set for the task and are used for learning how to solve this task.
In addition, there are further examples of the same classes, known as a query set, which are used to evaluate the performance on this task. Each task can be completely non-overlapping; we may never see the classes from one task in any of the others. The idea is that the system repeatedly sees instances (tasks) during training that match the structure of the final few-shot task but contain different classes.
At each step of meta-learning, we update the model parameters based on a randomly selected training task. The loss function is determined by the classification performance on the query set of this training task, based on knowledge gained from its support set. Since the network is presented with a different task at each time step, it must learn how to discriminate data classes in general rather than a particular subset of classes.
To evaluate few-shot performance, we use a set of test tasks. Each contains only unseen classes that were not in any of the training tasks. For each, we measure performance on the query set based on knowledge of their support set.
Source: https://www.borealisai.com/en/blog/tutorial-2-few-shot-learning-and-meta-learning-i/
GPT-3 Training
The authors found that GPT-3 could generate samples of news articles which human evaluators had difficulty distinguishing from articles written by humans. This finding underscores the potential of language models like GPT-3 to produce content that is indistinguishable from human-written text.
Few-shot learning has numerous real-world applications across various domains. Here are a few examples:
- -Medical Imaging: Few-shot learning can be particularly useful in medical imaging for diagnosing rare diseases. For instance, in the case of COVID-19, a computer vision model trained with few-shot learning techniques could classify an image of a chest X-ray accurately after being exposed to a small number of X-ray images 5.
- -Natural Language Processing (NLP): Few-shot learning can be applied to various NLP tasks like text classification, sentiment analysis, and language translation. For instance, few-shot learning algorithms could learn to classify text into different categories with only a small number of labeled text examples. This approach can be particularly useful for tasks in the area of spam detection, topic classification, and sentiment analysis 1.
- -Audio Processing: Few-shot learning can enable tasks such as voice cloning from a few audio samples of the user (e.g., voices in GPS/navigation apps, Alexa, Siri, etc.), voice conversion from one user to another, and voice conversion across different languages 3.
- -Robotics: Few-shot learning plays a critical role in training robots to complete certain tasks such as learning a movement by imitating a single demonstration, learning manipulation actions from a few demonstrations, visual navigation, and continuous control 3.
- -Image Generation: Few-shot learning can be used for tasks such as image retrieval, image generation, image captioning, scene location recognition, and shape view reconstruction for 3D objects 3.
These are just a few examples. The versatility of few-shot learning makes it applicable in many other areas as well.
Are there any limitations to using few-shot learning?
Yes, there are several limitations to using few-shot learning:
- Performance on Complex Tasks: Few-shot learning algorithms often struggle with complex tasks that require deep understanding and reasoning. This is because these tasks often require a larger amount of data to capture the underlying patterns and structures effectively 2.
- Difficulty with One-Shot Learning: One-shot learning, a subset of few-shot learning where only one example is provided per class, is particularly challenging. This is because the model has very little information to learn from, making it difficult to accurately classify new instances.
- Need for High-Quality Examples: Few-shot learning requires high-quality examples to learn effectively. If the support set contains misleading or irrelevant examples, the model's performance can degrade significantly. This highlights the importance of careful selection and annotation of training data.
- Reliance on Pre-trained Models: Few-shot learning often relies on pre-trained models, which can limit the flexibility of the learning process. Moreover, the quality of the pre-training phase significantly influences the performance of few-shot learning, which adds another layer of complexity.
- Challenges with Explainability: Explaining the decisions made by few-shot learning models can be challenging. This is because these models often operate in high-dimensional spaces and use complex algorithms to make predictions. As a result, it can be difficult to understand why a particular decision was made, which is crucial for trust and accountability in many applications. Source: https://blog.paperspace.com/few-shot-learning/
In conclusion, the paper "Language Models are Few-Shot Learners" presents compelling evidence that scaling up language models can significantly improve task-agnostic, few-shot performance. This achievement brings us closer to the goal of creating AI systems that can learn effectively from a small number of examples, much like humans. However, further research is needed to address the challenges and limitations identified in the study.