August 16, 2024
Attention Is All You Need
By: Ashish Vaswani et al. published in the 31st Conference on Neural Information Processing Systems (NIPS 2017)
Link: https://arxiv.org/pdf/1706.03762.pdf
Understanding "Attention is All You Need"
In the rapidly evolving world of Artificial Intelligence, one model stands out for its remarkable impact: the Transformer. Introduced in the groundbreaking paper 'Attention Is All You Need' by Vaswani et al., this model has redefined how machines understand and process human languages. But why is this important, and what makes the Transformer model so revolutionary? We will aim to demystify the complexities of the Transformer, offering beginners a clear and concise understanding of one of the most influential developments in NLP.
What is Attention?
Before diving into the specifics of the Attention Mechanism, let's first understand what attention means in general. In the context of machine learning and natural language processing, attention refers to the ability of a model to focus on certain parts of the input data when generating an output. This focus is determined by a measure called attention scores, which indicate the relevance of different parts of the input data to the current output. The Attention Mechanism
The Attention Mechanism is a crucial component of Transformer models, which were introduced in the "Attention is All You Need" paper. Unlike traditional neural network architectures like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), Transformers process all inputs simultaneously, making them highly parallelizable and enabling faster training times. However, unlike CNNs, Transformers don't have any form of spatial hierarchy, which makes them struggle to capture long-range dependencies.
This is where the Attention Mechanism comes in. It allows the model to weigh the importance of different parts of the input data when generating an output. Specifically, it computes an attention score for each input position, indicating how much focus should be placed on that position when producing the corresponding output position. How Does Attention Work?
The Attention Mechanism works by taking three inputs: keys, values, and queries. Each of these inputs is a vector that is associated with each input position. The attention score for a given input position is calculated as the dot product of the query vector and the key vector, followed by a softmax function to ensure the scores sum up to one. The final output is a weighted sum of the value vectors, where the weights are the attention scores.
Here's a simplified version of the Attention Mechanism:
import torch
import torch.nn.functional as F
def attention(query, key, value):
# Compute the dot product of the query and key
scores = torch.matmul(query, key.transpose(-2, -1))
# Apply the softmax function to get the attention scores
attention_scores = F.softmax(scores, dim=-1)
# Compute the weighted sum of the value vectors
output = torch.matmul(attention_scores, value)
return output, attention_scores
Self-Attention Explained in Detail

This Self-Attention Mechanism allows the model to weigh the importance of each input position when producing the output, thereby enabling it to focus on the most relevant parts of the input sequence
How does the use of attention in transformer models differ from traditional RNNs and CNNs?
The use of attention in Transformer models differs significantly from traditional Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs).
In RNNs, attention is typically used to address the problem of vanishing and exploding gradients, which make it difficult for the model to remember information from distant steps in the sequence. Attention in RNNs allows the model to focus on different parts of the input sequence when generating an output, thus improving the model's performance on tasks like machine translation and sentiment analysis.
However, RNNs inherently suffer from slow training speeds due to their sequential nature, and they often require truncation techniques like Truncated Back Propagation In Time to prevent gradients from becoming too large.
On the other hand, Transformer models, introduced in the "Attention is All You Need" paper, utilize attention differently. Instead of focusing on a specific part of the input sequence when generating an output, Transformers calculate attention scores for all input positions simultaneously. This simultaneous computation of attention scores across the entire sequence allows Transformers to capture long-range dependencies more effectively than RNNs.
Unlike RNNs, Transformers do not have a built-in mechanism for handling the order of the sequence. Therefore, they use positional encoding to understand the order of the sequence. This allows Transformers to capture the relationships between different parts of the sequence.
Moreover, Transformers use a mechanism called multi-head attention, which allows the model to focus on different parts of the input sequence multiple times with different learned linear transformations. This allows the model to capture various aspects of the input sequence simultaneously.
In contrast to CNNs, which are primarily used for image processing tasks, Transformers are designed for sequence-to-sequence tasks such as machine translation and text summarization. They excel in these tasks because they can capture the dependencies between different parts of the sequence, which is critical for understanding the semantic meaning of the input data.
While attention is used in RNNs to improve their performance on sequence-to-sequence tasks, Transformer models use attention differently, focusing on all parts of the input sequence simultaneously and allowing for the capture of long-range dependencies.
Previous models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) have several limitations:
Vanilla RNNs:
Vanilla RNNs have limited representational power, which can make it difficult for them to learn complex patterns in sequential data 2.Due to the limitations of short-term memory and vanishing gradients, vanilla RNNs have difficulty in learning long sequences. Vanilla RNNs are inherently sequential in nature, which makes it difficult to parallelize their computations. This can limit their efficiency in processing large amounts of data.
LSTMs:
While LSTMs are an improvement over vanilla RNNs as they can learn long-term dependencies due to their gating units, they still face the challenge of learning long sequences. This is due to the fact that even though LSTMs have a larger capacity compared to vanilla RNNs, they can still suffer from similar issues like vanishing and exploding gradients. Another limitation of LSTMs is that they can be computationally expensive, especially when processing long sequences. This can make it difficult to train large models on limited hardware
These limitations led to the development of Transformer models.
Key Components of the Transformer model:
Transformers, introduced in the "Attention is All You Need" paper, consist of three key components: the Self-Attention Mechanism, Positional Encoding, and the Encoder-Decoder Architecture. Let's delve into each of these components.
Self-Attention Mechanism:
We've already discussed the Self-Attention mechanism, but here's a quick summary: The Self-Attention Mechanism is the core of the Transformer model. It allows the model to weigh the importance of each element in the input sequence relative to every other element. This attention score is computed using a dot product operation between the query and key vectors, followed by a softmax function to ensure the scores sum up to one. The final output is a weighted sum of the value vectors, where the weights are the attention scores.
Positional Encoding:
While the Self-Attention Mechanism does not consider the order of elements in the input sequence, the order is indeed important as it carries important information. To account for this, Transformers introduce Positional Encoding. This technique adds positional information to the input embeddings, allowing the model to understand the order of the sequence.
Encoder-Decoder Architecture:
The Transformer model follows an Encoder-Decoder architecture. The Encoder processes the input data and translates it into a sequence of vectors, which are rich representations that capture the essence of each data point. The Decoder, on the other hand, takes the processed materials from the Encoder and generates the output. The Decoder reads the sequence of vectors and generates the output, whether that’s a translation, a summary, a response, or another form of processed data.
Each of these components plays a crucial role in the Transformer model, contributing to its ability to handle sequence-to-sequence tasks effectively.
Transformer models have shown superior performance in several sequence-to-sequence tasks. Here are a few examples:
Machine Translation:
Machine translation is a classic sequence-to-sequence task where the goal is to translate a sentence from one language to another. Traditional RNN-based models had difficulties with longer sentences due to the vanishing gradient problem. However, Transformer models, with their attention mechanisms, have demonstrated superior performance in machine translation tasks. They are capable of handling longer sentences and complex language structures more effectively.
Text Summarization:
Text summarization involves condensing a large piece of text into a shorter version that retains the main ideas. Transformer models, with their self-attention mechanism, have shown great success in this task. They are able to identify and emphasize the most important parts of the text during the summarization process.
Speech Recognition:
Speech recognition is another sequence-to-sequence task where the goal is to convert spoken words into written text. Transformer models have been used successfully in this area, providing better performance than traditional RNN-based models. They are capable of handling the temporal dynamics of speech signals and capturing long-range dependencies in the audio data.
Chatbot Dialogues:
Chatbots communicate with users in a conversational manner, which involves mapping user input to appropriate responses. Transformer models have been used to build chatbots that can generate coherent and contextually relevant responses. Their ability to handle long-range dependencies and maintain context makes them suitable for this task.
Transformer models have shown superior performance in various sequence-to-sequence tasks due to their ability to handle long-range dependencies and maintain context
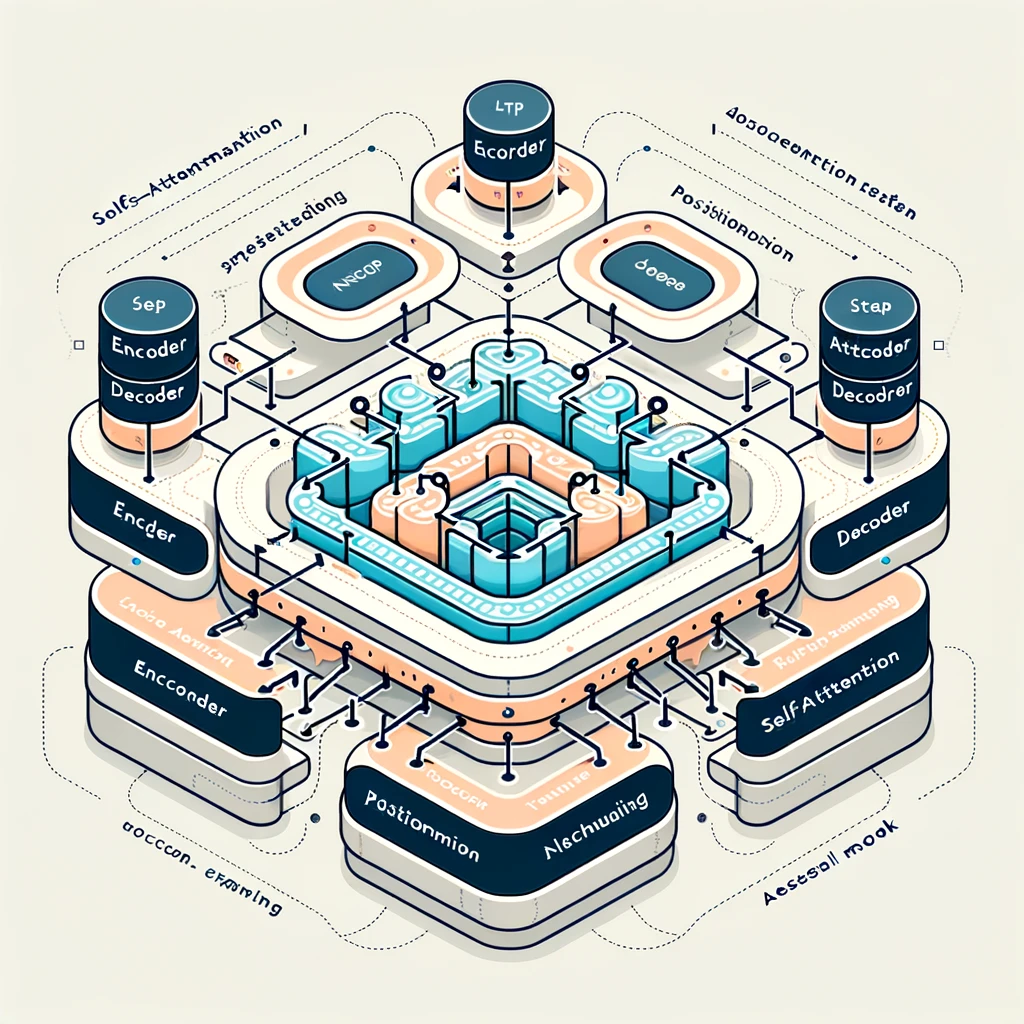
The image above illustrates the basic architecture of the Transformer model, suitable for inclusion in your article. It visually represents the key components such as encoder and decoder stacks, self-attention mechanisms, positional encoding, and how data flows through these components.
The Future of Natural Language Processing with Transformers
The future of Natural Language Processing (NLP) looks promising with the continued evolution and improvement of Transformer models. These models have revolutionized NLP, enabling a new wave of applications such as chatbots, sentiment analysis, machine translation, and more.
One of the key areas of growth in NLP is the integration of Multi-Task Learning (MTL) with Transformers. MTL allows models to learn from related tasks concurrently, reducing computational overhead and resource requirements. This leads to improved performance on individual tasks and makes Transformer models particularly adaptable to varied language tasks.
Another exciting direction in NLP is the development of Continual Multi-Task Learning (CMTL), which integrates Continual Learning (CL) with MTL. CL is about models adapting over time to new data or tasks, addressing the issue of "catastrophic forgetting" where learning new information can lead to the loss of previously acquired knowledge. CMTL holds the promise of models that not only handle multiple tasks efficiently but also continually adapt and evolve with the changing landscape of language and communication.
Furthermore, Transformers have shown remarkable ability to understand and generate human-like text responses, opening up new possibilities in NLP. As a result, the future of NLP holds immense potential for both practical applications and research breakthroughs, continually pushing the boundaries of what artificial intelligence can achieve in language understanding.
The Power of Attention
The Attention Mechanism has proven to be extremely powerful. It has enabled the development of models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer), which have achieved state-of-the-art performance on a wide range of Natural Language Processing tasks.
However, despite its advantages, the Attention Mechanism is not without its challenges. It requires a lot of computational resources, especially when dealing with long sequences. Moreover, it struggles to handle tasks that require understanding of the entire input data, such as image recognition.
Despite these challenges, the Attention Mechanism remains a fundamental concept in modern machine learning and continues to drive innovation in the field. Whether you're just starting out in machine learning or you're an experienced researcher looking for new techniques to explore, understanding the Attention Mechanism could be a valuable addition to your toolkit.
So, in simple terms: The Transformer is like a new, super-fast race car, while the older methods are like regular cars. The Transformer can win races while using less fuel!
For more reading, refer here: